Managing the Lifecycle of your Elasticsearch Indices
Just like me, you are probably storing your [Applications | Infrastructure | IoT ] Logs / Traces (as a time series) into Elasticsearch or at least considering doing it.
If that is the case, you might be wondering how to efficiently manage index lifecycles in an automated and clean manner, then this post is for you!
What’s happening?
Basically, this means that your log management/aggregator applications are storing the logs in Elasticsearch using the timestamp (of capture, processing, or another one) for every record of data and grouping, using a pattern for every group.
In Elasticsearch terms, this group of logs is called index and the pattern is referring commonly to the suffix used when you create the index name, e.g.: sample-logs-2020-04-25.
The problem
Until here everything is ok, right? so the problems begin when your data starts accumulating and you don’t want to spend too much time/money to store/maintain/delete it.
Additionally, you may be managing all the indices the same, regardless of data retention requirements or access patterns. All the indices have the same number of replicas, shards, disk type, etc. In my case, it is more important the first week of indices than the indices three months old.
As I mentioned before, depending on your index name and configuration, you will end up with different indexes aggregating logs based on different timeframes.
It is likely that just like I was doing few months back, you are using your custom Script/Application implementing the Elasticsearch Curator API or going directly over the Elasticsearch index API to delete or maintain your indices lifecycle or worst, you are storing your indices forever without any kind of control or deleting it manually.
My logs cases
Case 1
Third-party applications that use their own index name pattern like indexname-yyyy-mm-dd and I cannot / I don’t want to change it. e.g. Zipkin (zipkin-2020-04-25)
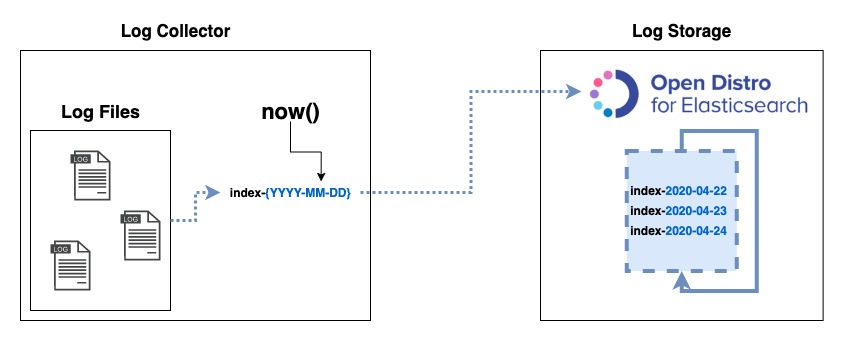
Case 2
My own log aggregator (custom AWS Lambda function) and/or third-party applications like fluentd, LogStash, etc. That allows me to change the index name pattern. So, in this case I can decide how to aggregate my logs and the index pattern name I want to use.
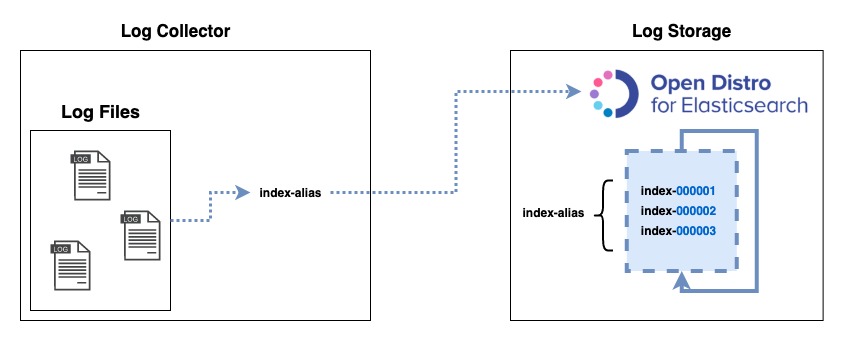
One more thing before moving on: The term used for Elasticsearch to create a index per day, hour, month, etc. is rollover.
The Solution
Preliminaries
In my case, I’m using AWS Elasticsearch Service which is a “little bit different” from the Elasticsearch Elastic since AWS decided to create their own Elasticsearch fork called Open Distro for Elasticsearch.
the key terms to understand “Index Lifecycle” in every Elasticsearch distribution is:
- Index State Management (ISM) → Open Distro for Elasticsearch
- Index lifecycle management (ILM) → Elasticsearch Elastic
ElasticSearch concepts are out of the scope of this post, in the below cases I will explain how Open Distro for Elasticsearch manages its indices lifecycle.
Case 1
… Remember above.
The log management/aggregation application makes the “rollover” of my indices, but I would like to delete/change those after the index has rolled — The most common
Create an Index State Management Policy to delete indices based on time and/or size and using an Elasticsearch Templates and Elasticsearch Aliases your Elasticsearch engine can delete your indices periodically.
And yes, the result is very similar to what I was doing with my custom AWS Lambda function in Python using Elasticsearch Curator API
But, without the hassle of writing any code, handling connection errors, upgrade my code every time my Elasticsearch was upgraded, credentials, changing the env vars to pass the new indices name, etc.
Now, thanks to ISM I can use a JSON declarative language to define some rules (policies) and the Elasticsearch engine is in charge of the rest.
Policies? … imagine you can implement this kind of rules
- Keep “my fresh indices” open to write for 2 days, then
- After the 2 first days, closes those indices for write operations and keep them until 13 days more, then
- 15 days after index creation, delete it forever, end
What does this means? well, after learning about the ISM Policies and using Kibana Dev Tool, I created a policy name delete_after_15d following the rules described above, and here you have it.
{kind=link}
| |
NOTE: Notice the highlighted lines, are these my rules described above?
Then using the following Elasticsearch Templates, I applied the policy (above), see template line (below) 8, to my indices following a pattern in the line 5
Now what? Is it ready?
For the new indices, yes. The indices created after you created this template into your Elasticsearch.
What about the old ones?
The indices created before applying the index template. For these we need to change its definition and add the line 5
But, how do I complete the tasks you mention before?
Don’t worry, keep calm!, here https://github.com/slashdevops/es-lifecycle-ism you have the complete explanation to apply this rule in your own Elasticsearch, also how to test it into an Elasticsearch instance or create it locally with docker-compose.
Case 2
My Elasticsearch rolls over the indices base on time and/or size and I want to have only one entry point (index) to send my logs — I think it is the best one
The rules again
- Rollover “my fresh indices” after 1 day, then
- Close those indices for write operations and keep it until 13 days more, then
- After 15 days of the index was created, delete it forever, end
Well, to do that I create an ISM policy named rollover_1d_delete_after_15 to control the state of my indices and using the rollover action.
| |
NOTE: Notice the highlighted lines, did you see the rollover action?
Then like in case 1, using the following Elasticsearch Templates, I applied the policy above, see template (below) line 7, to my indices following a pattern in the line 5.
| |
What does it means?
Now Elasticsearch Engine will be in charge of rollover the indices and you don’t need to create any index name pattern when indexing your data over Elasticsearch, in other words, your Application logs’ aggregator doesn’t need to rollover your indices.
The last step and obligatory to trigger all the rollover processes inside Elasticsearch, it creates the first rollover index according to the template and aliases defined inside this.
So, How do I index my data now?
Using the rollover alias (template definition above line 5) created in the Elasticsearch template. Now you have only one index name (index alias) to configure your Custom Program / LogStash / Fluentd, etc and you can forget the suffix pattern.
Here is an example of how to insert data using the rollover index alias:
| |
Conclusions
If you have Elasticsearch as your logs storage and index platform and you never used before or heard about it:
- Index State Management (ISM) → Open Distro for Elasticsearch
- Index lifecycle management (ILM) → Elasticsearch Elastic
Then, Go fast and learn how to apply this to improve your everyday job.
Acknowledgements
This was possible thanks to my friend Alejandro Sabater, who took his free time to review it and share its recommendation with me.